Linux下YOLOv5的配置与使用
YOLOv5环境搭建及使用。
算法介绍
YOLOv5是一种流行的单阶段(One-Stage)目标检测算法,它以其速度快和准确率高而受到广泛关注。YOLOv5的全称是”You Only Look Once version 5”,意味着该算法只需一次查看图像就能检测出其中的目标。
环境配置
下载
到github下载源码
Github:https://github.com/ultralytics/yolov5
然后解压下载的压缩包,解压后的默认文件夹是yolov5-master,当然也自己可以随意命名。
可以在下图,下载最新更新的项目: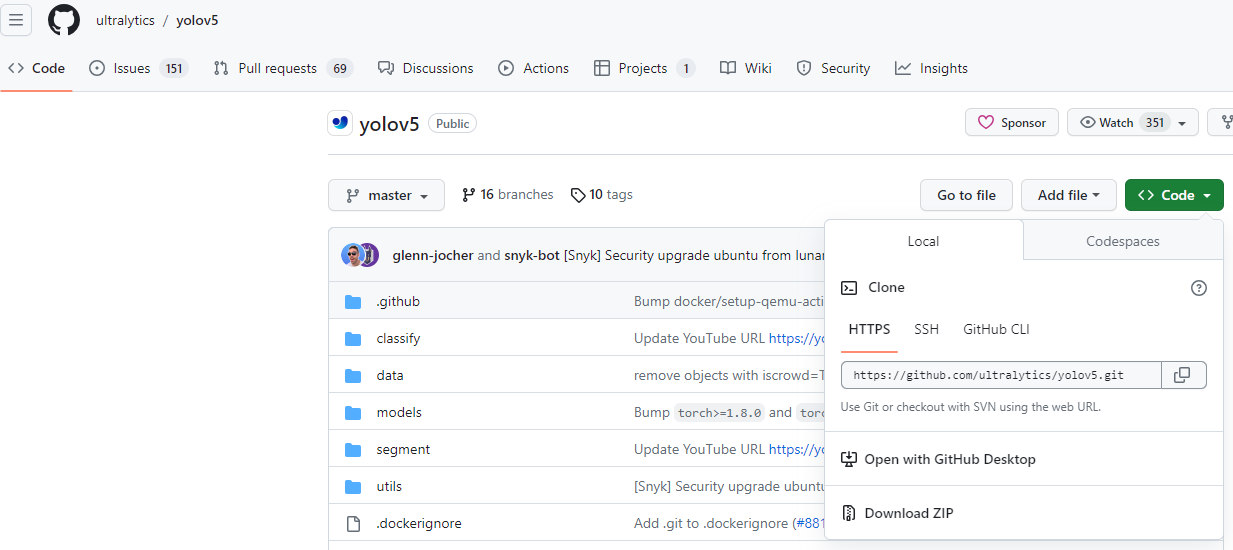
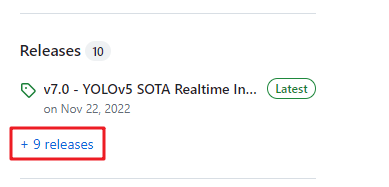
也可以在下图,下载需要的项目版本(Source code的zip和tar.gz压缩格式,二选其一即可):
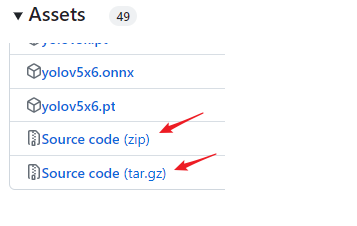
下载权重文件
下载权重文件,其实是yolo的预训练模型。
Github:https://github.com/ultralytics/yolov5/releases
YOLOv5根据参数量分为了n、s、m、l、x五种类型,其参数量依次上升,当然了其效果也是越来越好。
n:Nano(最小),s:Small(小),m:Medium(中),l:large(大),x:Extra Large(超大)。
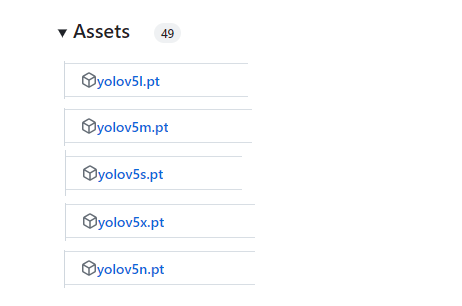
在yolov5-master文件夹下新建pretrained文件夹,将权重文件放进来。
配置
推荐先创建虚拟环境。如果安装了Anaconda(简称:conda),则先创建虚拟环境、激活虚拟环境,再继续下面的操作。
也可以使用Python的venv模块 创建虚拟环境。
若不使用使用虚拟环境,则直接进行下面的步骤。- 安装pytorch和torchvision。到 PyTorch官网 选择合适的pytorch版本,取得相应的安装命令,然后安装torch和torchvision。
由于服务器没有GPU,下面是一个CPU版本的安装示例:1 2 3 4
使用conda命令: conda install pytorch torchvision cpuonly -c pytorch 或者使用pip命令: pip install torch==1.12.0 torchvision==0.13.0 torchaudio==0.12.0
- 在Terminal中使用命令,cd到解压得到的文件夹之内,有一个
requirements.txt文件,将其中的torch和torchvision的信息注释掉(使用#号注释)
执行命令,安装其他需要的库:1
pip isntall -r requirements.txt - pycocotools用于计算目标检测的精度、mAP。
安装pycocotools:1 2
Linux下安装: pip install pycocotools Windows下安装: pip install pycocotools-windows
PyQt5用来搭建(图形化)界面。
安装PyQt5:1
pip install PyQt5 - opencv(requirements.txt中有此库的话,可以跳过此步)
安装命令:1
pip install opencv-python - 安装matplotlib可视化库(requirements.txt中有此库的话,可以跳过此步)
命令:1
pip install matplotlib
初步使用
初步使用,同时测试是否配置成功。
data/images/目录下有两张图片,其中一个是bus.jpg,下面使用bus.jpg进行测试。
运行python程序detect.py
执行命令:
1
python detect.py --source data/images/bus.jpg --weights pretrained/yolov5s.pt</p>
程序会创建runs文件夹,runs/detect/exp/目录下的图片bus.jpg是程序输出的结果。每运行一次detect.py,就会产生一个用来存放结果的新文件夹。
程序执行时报错
运行python程序detect.py,执行detect.py检测命令时,yolov5 程序运行报错:ImportError: libGL.so.1: cannot open shared object file: No such file or directory。
解决方法:
- 方法1
apt-get update
apt-get install ffmpeg libsm6 libxext6 -y - 方法2(不一定管用)
pip uninstall opencv-python
pip install opencv-python-headless
数据标注
LabelImg是一款图像标注工具,可方便创建自己的数据集,方便进行深度学习训练。它是用Python编写的,并将Qt用于其图形界面。
安装命令:
1
2
3
4
# 启动虚拟环境:
conda activate 虚拟环境名称
# 安装:
pip install labelimg
启动labelimg:命令行输入labelimg,然后回车。
也可以去Github下载:https://github.com/HumanSignal/labelImg
可能会报错:qt.qpa.plugin: Could not load the Qt platform plugin “xcb“ in ““ even though it was found
这句话意思是Qt应用程序时缺少xcb平台插件。
这可能是因为未安装相应的Qt平台插件库,或者环境变量未正确设置。
可以通过以下命令解决:
sudo apt-get install libxcb-xinerama0
模型训练
1
python train.py --data mask_data.yaml --cfg mask_yolov5s.yaml --weights pretrained/yolov5s.pt --epoch 100 --batch-size 4 --device cpu
模型评估
1
python val.py --data data/mask_data.yaml --weights runs/train/exp_yolov5s/weights/best.pt --img 640
模型使用
1
2
3
4
5
6
7
8
9
10
11
12
# 检测摄像头
python detect.py --weights runs/train/exp_yolov5s/weights/best.pt --source 0 # webcam
# 检测图片文件
python detect.py --weights runs/train/exp_yolov5s/weights/best.pt --source file.jpg # image
# 检测视频文件
python detect.py --weights runs/train/exp_yolov5s/weights/best.pt --source file.mp4 # video
# 检测一个目录下的文件
python detect.py --weights runs/train/exp_yolov5s/weights/best.pt path/ # directory
# 检测网络视频
python detect.py --weights runs/train/exp_yolov5s/weights/best.pt 'https://youtu.be/NUsoVlDFqZg' # YouTube video
# 检测流媒体
python detect.py --weights runs/train/exp_yolov5s/weights/best.pt 'rtsp://example.com/media.mp4' # RTSP, RTMP, HTTP stream